Node 核⼼内容
在 Node.js 中,全局对象是 global 对象。全局对象上的可以直接访问,但是在模块中我们可以直接访问,exports、require、module、filename、dirname,均为函数的参数,我们可以在模块内部直接访问这些变量,但是它们并不是全局对象上的属性。
1.Global
node 中的全局对象 global , this 不是 global,指代的是当前模块的导出对象.
在 Node.js 中,通过在变量前⾯加上 global 关键字来声明全局变量。
通过 var 声明的变量不会挂载到全局上。
全局变量可以再不同模块中进⾏访问。
不建议在代码中使⽤全局变量,会污染全局环境。
全局属性, 可以通过 global 直接访问 (可以不再模块内被访问)
process
setImmediate
setTimeout
Buffer
2.Process
process.cwd: 当前的工作目录, 会根据执行文件的位置发生变化 尽量读取文件采用绝对路径__dirname不能变process.platform: 平台标识 win32 和 darwinprocess.env.NODE_ENV: 环境变量,通过 cross-env 可以设置不同平台的环境变量。(终端环境变量export NODE_ENV=dev、系统环境变量~/.bash_profile)
console.log(process.env.NODE_ENV)
let url = ""
if (process.env.NODE_ENV == "dev") {
url = "http://localhost:3000"
} else {
url = "http://xxx.cn"
}
process.argv:获取⽤户传递的参数
webpack --config webpack.config.js --port 3000 --hot
argv 前两个参数一般用不到
- node 的可执行文件
2) 当前要执行的文件
一般情况下参数的短写 -p 长些--port 值不用-,key 得用-
console.log(process.argv)
转换成对象
let args = process.argv.slice(2).reduce((memo, current, index, array) => {
if (current.startsWith("--")) {
memo[current.slice(2)] = array[index + 1]
? array[index + 1].startsWith("--")
? true
: array[index + 1]
: true
}
return memo
}, {})
console.log(args)
第三⽅模块可以来实现这些功能 commander,yargs,minimist
const { program } = require("commander")
const pkg = require("./package.json")
program.name("my-cli") // 发布的命令名字
program.usage("<command> [options]") // 使⽤⽅式
program.version(pkg.version)
program
.command("create") // 创建项⽬
.description("create directory") // 描述
.option("-d, --directory <d>", "createproject directory") // 参数
.action((args) => {
// 执⾏的动作
console.log(args)
})
.on("--help", () => {
console.log("create project~~~")
})
program
.command("serve") // 启动服务
.description("starrt server")
.option("-p, --port [p]", "serverport", 3000)
.action((args) => {
console.log(args)
})
program.on("--help", function () {
console.log("\n Run my-cli <command> --help.")
})
program.parse()
3.Node中的事件环
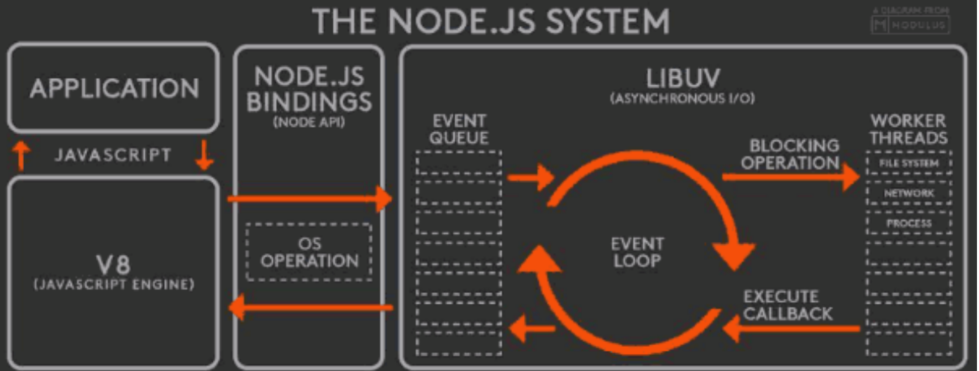
我们写的 js 代码会交给 v8 引擎进⾏处理
代码中可能会调⽤ nodeApi,node 会交给 libuv 库处理
libuv 通过阻塞 i/o 和多线程实现了异步 io
通过事件驱动的⽅式,将结果放到事件队列中,最终交给我们的应⽤。
本阶段执⾏已经被 setTimeout() 和 setInterval()的调度回调函数。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
| 执⾏延迟到下⼀个循环迭代的 I/O 回调。
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
| 仅系统内部使⽤。
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘
| 检索新的I/O事件;执⾏与 I/O相关的回调 ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
| setImmediate() 回调函数在这⾥执⾏。 └───────────────┘
│ ┌─────────────┴─────────────┐
│ │ check │
│ └─────────────┬─────────────┘
| ⼀些关闭的回调函数
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
这⾥每⼀个阶段都对应⼀个事件队列,当 event loop 执⾏到某个阶段时会将当前阶段对应的队列依次执⾏。当该队列已⽤尽或达到回调限制,事件循环将移动到下⼀阶段。
process.nextTick() 从技术上讲不是事件循环的⼀部分。优先级⾼于微任务
浏览器:每执行完毕一个宏任务,会清空微任务 从 node10+ 后执行机制和我们的浏览器一样 新的
以前的 node 事件环是每个阶段的宏任务都被清空了,才会执行微任务 老的
宏任务
- timers 队列 用来放定时器
- poll 轮训(处理 i/o 的回调)
- check 处理 setImmediate
微任务:process.nextTick > promise.then
Promise.resolve().then(()=>{
console.log('promise')
})
process.nextTick(()=>{ // 这个方法用的多一些
console.log('nextTick')
})
执行流程
主栈代码执行完毕-》会检测 timer 中有没有回调,全部清空后进入到下一个阶段 -》poll(有 i/o 的回调继续处理)-> 看有没有 check,如果有就清空
默认如果没有 check 也没有 timer,代码逻辑还有没执行完的回调,此时这个线程会在 poll 中等待
如果没有 timer -》 poll(有 i/o 的回调继续处理)-》 没有 check 了
poll 阶段:
检测 Poll 队列中是否为空,如果不为空则执⾏队列中的任务,直到超时或者全部执⾏完毕。
执⾏完毕后检测 setImmediate 队列是否为空,如果不为空则执⾏ check 阶段,如果为空则等待时间到达。时间到达后回到 timer 阶段
等待时间到达时可能会出现新的 callback,此时也在当前阶段被清空
setTimeout(() => { // 执⾏顺序不确定
console.log('settimeout')
})
setImmediate(() => {
console.log('check')
})
const fs = require('fs');
fs.readFile('./package.json', () => { // poll阶段的下⼀个阶段是check
setTimeout(() => { // timer
console.log('settimeout')
})
setImmediate(() => { // check
console.log('check')
})
});
4.Buffer
1).为什么需要 Buffer?
Buffer 对象在 Node.js 中是⽤来处理⼆进制数据的,展现形式是 16 进制。有了 Buffer 之后让 js 拥有处理⼆进制数据的能⼒。(Blob 不能对⽂件进⾏处理,ArrayBuffer 不能直接读取⼆进制数据,buffer 直接可以处理⼆进制数据)
2).进制转换
二进制 0b 开头 八进制 0 开头 十六进制 0x 开头
一般情况下,一个字节,也就是 1b, 1b = 1bit(每一个位可以存储 0 或者 1 1024b = 1kb 1024kb = 1M
- 任意进制转换成 10 进制 采⽤乘权求和的⽅式 parseInt('0111',2)
// 111 是二进制 -》3 10进制 1x2^2 + 1x2^1 + 1*2^0 -> 7
// 111 是16进制 -》17 10进制
// 乘权求和 1 * 16 ^2 + 1 * 16 ^1 + 1 * 16 ^0 = 273
// 1111111111 + 1 -1 = 1 * 2 ^ 10 -1
console.log(parseInt("1111111111", 2)) // 这个方法可以将任何进制转化成10进制
// toString 可以转换任何进制 转出来的是字符串
- 10 进制转任意进制 采⽤反向取余的⽅式(100).toString(16)
// 反向取余的方式来计算
// 100 -> 16 -> 64
console
.log((100).toString(16))(
// 64
0x11
)
.toString(2) //'10001'
- 10 进制⼩数转⼆进制 采⽤乘取 2 整法的⽅式 (0.1).toString(2)
思考:0.1 + 0.2 !== 0.3
// 0.1 + 0.2 !== 0.3 -> 二进制来存储 10进制的小数如何转化成2进制
// 乘2取整法
// 0.1 * 2 = 0.2
// 0.2 * 2 = 0.4
// 0.4 * 2 = 0.8
// 0.8 * 2 = 1.6
// 0.6 * 2 = 1.2
// 0.2 * 2 = 0.4
// 0.00011001001001001
console.log((0.1).toString(2)) //'0.0001100110011001100110011001100110011001100110011001101'
console.log(0.1 + 0.2) // 0.30000000000000004
console.log(0.2 + 0.2) // 都是近似值 0.4
3).字符编码
ASCII:最早采⽤ ASCII,是⼀种 7 位的编码⽅式,最多⽀持 128 个字符(只能处理英⽂字符和⼀些常⽤的符号)
GB2312(国标字体):简体中⽂字符编码,两个字节表示( 两个⼤于 127 的字符连在⼀起时,就表示⼀个汉字) 为中国⽽⽣,⼤概⽀持 6000 多个汉字。(255-127)*(255-127)
GBK 双字节 只要第一个字节超过了 127 我就认为下一个字节就是汉字的另一个部分 繁体。⽀持了繁体、⽇语、韩语等((255)*(255-127)) 半角和全角问题
GB18030 在 GB2312 和 GBK 基础上更全⾯
Unicode 使⽤ 16 位来统⼀表示所有的字符 (将⽂字全部重写重拍) (255*255)
UTF-8 对 Unicode 编码进⾏编码,
编程 1-4 个可变长度的字节 10w+字符。 可变在 utf-8 一个字母是一个字节 一个汉字是 3 个字节
结论:GB 编码中 1 个汉字是 2 个字节,在 utf8 编码中⼀个汉字是 3 个字节(常⻅的 ASCII 字符,使⽤⼀个字节表示)。
node 中默认不⽀持 GB 编码
4).base64 编码
为什么要进行编码
base64 编码 (编码格式) 明文,按照大家都知道的规则进行的转化
base32http 文本格式的协议 将二进制进行编码传输 -》字符串
将 1 个文字 3 * 8 个位 = 24 位
console.log(Buffer.from("帅")) // e5 b8 85
// 16进制转2进制
console.log((0xe5).toString(2))
console.log((0xb8).toString(2))
console.log((0x85).toString(2))
// 11100101 10111000 10000101
// // 111001 011011 100010 000101 3 * 8 = 4 *6
// 2 进制转换为10 进制
console.log(parseInt("00111001", 2)) //57
console.log(parseInt("00011011", 2)) //27
console.log(parseInt("00100010", 2)) // 34
console.log(parseInt("00000101", 2)) //5
// 中⽂编码取值表 64个
let code = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
code += code.toLowerCase()
code += "0123456789"
code += "+/"
console.log(code[57] + code[27] + code[34] + code[5]) //5biF
// 缺点 3个字节变为4个字节 3个 -》 4个 1M -》 1.3M
console.log(Buffer.from("帅").toString("base64")) // 5biF
base64 的优缺点:Base64 是将⼆进制转换成⽂本字符串,⽅便传输。缺点就是转换成 base64 编码的结果⽐以前⼤ 1/3。
5 . Buffer 的使⽤
buffer 代表的是内存中存的二进制数据 (buffer 中存放的都是引用类型)
buffer 一但声明了大小之后 不能更改声明的大小
1).buffer 的声明⽅式
buffer 的声明方式 3 种
- 通过长度来声明
2) 通过数组方式来声明(基本不用) 3) 通过字符串来声明 new Buffer
const buf1 = Buffer.alloc(3) // // 根据⻓度来声明buffer 在开发中都是以字节为单位的, 展现形式是16进制
console.log(buf1) // <Buffer 00 00 00>
const buf2 = Buffer.from([0x10, 0x20, 0x30]) // 通过指定存储内容来声明
console.log(buf2) //<Buffer 10 20 30>
const buf3 = Buffer.from("你好") // 通过字符串来声明buffer
console.log(buf3) //<Buffer e4 bd a0 e5 a5 bd>
2).buffer.copy
buffer 的扩容问题 http 请求传输二进制的时候 就是一段段
const buf1 = Buffer.from("你好")
const buf2 = Buffer.from("世界")
// buffer 可以通过长度(字节长度)和索引来访问
// (经常会将多个buffer拼接成一个buffer)
// 1) 断点续传, 分片上传 -》 大段
// 2) http请求也是分段传输的
const big = Buffer.alloc(buf1.length + buf2.length)
buf1.copy(big, 0)
buf2.copy(big, buf1.length)
console.log("big=>", big) //big=> <Buffer e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c>
console.log(big.toString()) // 你好世界
模拟实现
Buffer.prototype.copy = function (
target,
targetStart,
sourceStart = 0,
sourceEnd = this.length
) {
for (let i = 0; i < sourceEnd - sourceStart; i++) {
target[targetStart + i] = this[sourceStart + i] // // buffer中存放的都是引⽤类型
}
}
3).Buffer.concat
const buf1 = Buffer.from("你好")
const buf2 = Buffer.from("世界")
console.log(Buffer.concat([buf1, buf2], 12))
模拟实现
Buffer.concat = function (
bufList,
total = bufList.reduce((acc, cur) => acc + cur.length, 0)
) {
// 内部需要创建buffer
const buf = Buffer.alloc(total)
let offset = 0
for (let i = 0; i < bufList.length; i++) {
const cur = bufList[i]
cur.copy(buf, offset)
offset += cur.length
}
// 我们可以将不需要的部分给删除掉,就是数组的slice
return buf.slice(0, offset)
}
4).buffer.split
slice 方法要慎重 截取某一段 , 对于 buffer 而言浅拷贝
const buf = Buffer.alloc(6)
console.log("buf", buf) //buf <Buffer 00 00 00 00 00 00>
const c = buf.slice(0, 1)
c[0] = 100
console.log("buf", buf) //buf <Buffer 64 00 00 00 00 00>
如果想生成一个新的 buffer 和原来的内容一样 应该采用的是创建一个新的 buffer,把内容粘贴进去,而不是采用 slice
常用的 buffer 方法
.length
.concat
isBuffer
.slice
.split 自己的
行读取器, 每次读取内容的一行。 数据传输 formdata
test.txt
abc
deg
ghx
main.js
Buffer.prototype.split = function (sep) {
// 在node中处理数据的时候 要保证数据格式是统一的
const arr = []
const sepLen = Buffer.isBuffer(sep) ? sep.length : Buffer.from(sep).length
let offset = 0
let cur = 0
while (-1 !== (cur = this.indexOf(sep, offset))) {
arr.push(this.slice(offset, cur))
offset = cur + sepLen // 从当前的截取的下一个分割符号的位置为开头继续查找
}
console.log(offset)
arr.push(this.slice(offset)) // 最后一段也要放进来
return arr
}
let arr = r.split("\r\n")
for (let i = 0; i < arr.length; i++) {
arr[i] = arr[i].toString()
}
console.log(arr) //[ 'abc', 'deg', 'ghx', '' ]
6.path 模块
const { resolve, join, dirname, extname, basename } = require("path")
// resolve 特点:返回绝对路径,但是如果你传递是一个相对路径,会根据用户执行的位置来转换成绝对路径 process.cwd()
console.log(resolve(__dirname, "./test.txt"))
console.log(resolve("./test.txt")) // console.log(resolve(process.cwd(),'./test.txt'))
// __dirname 是node中commonjs实现的时候 给函数添加的参数,在node环境下如果你要是使用了commonjs
// 正常情况下 join和resolve能用不同的写法达到同样的目的,但是如果有/的情况,要拼接只能采用join方法
console.log(resolve(__dirname, "./test.txt", "/")) // /
console.log(join(process.cwd(), "a", "b", "c", "../")) // 不会产生绝对路径
console.log(dirname("a/b/c/")) // a/b
console.log(extname("a.js")) //.js
console.log(basename("a.js", "s")) // a.j
在 mjs 中处理路径的注意点,mjs 中没有dirname,filename。需要通过 import.meta.url 中来获取当前⽂件路径。(mjs 原理:node 中进⾏加载时会创建⼀个新的作⽤域,在内部运⾏模块代码)
01.mjs
import path from "path" // mjs -> esModule 在node中是自己实现的模块加载器,本质上就是给每个模块增加了立即执行函数
//import url from 'url'; // url里的parse可以直接进行解析
// const obj = url.parse(import.meta.url)
const obj = new URL(import.meta.url) // 就是将路径转换成对象,取他的核心path
let dirname = path.dirname(obj.pathname)
console.log(dirname, obj.pathname)
7.events 模块
node 中提供的发布订阅模式 实现异步处理。 解耦合
如何继承原型上的方法
Object.create()
Object.setPrototypeof
Girl.prototype.proto = EventEmiter.prototype
Girl extends EventEmitter\
手动触发
const EventEmitter = require("events")
function Girl() {}
Object.setPrototypeOf(Girl.prototype, EventEmitter.prototype)
let girl = new Girl()
girl.on("⼥⽣失恋了", () => {
console.log("狂吃")
})
girl.on("⼥⽣失恋了", () => {
console.log("逛街")
})
girl.on("⼥⽣失恋了", () => {
console.log("哭哭哭")
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
girl.emit("失恋")
girl.emit("失恋")
girl.emit("睡觉")
// 逛街 吃饭 哭 逛街 吃饭 哭 不哭
自动触发
const EventEmitter = require("events")
function Girl() {}
Object.setPrototypeOf(Girl.prototype, EventEmitter.prototype)
let girl = new Girl()
girl.on("⼥⽣失恋了", () => {
console.log("狂吃")
})
girl.on("⼥⽣失恋了", () => {
console.log("逛街")
})
girl.on("⼥⽣失恋了", () => {
console.log("哭哭哭")
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
// 逛街 吃饭 哭 逛街 吃饭 哭 不哭
自动触发
process.nextTick(() => {
girl.emit("失恋")
})
process.nextTick(() => {
girl.emit("睡觉")
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
//逛街 吃饭 哭 不哭
newListener 事件
girl.on("newListener", function (type) {
console.log(type, ",每次都触发") //每次绑定事件都会触发此方法
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
异步绑定
girl.on("newListener", function (type) {
//每次绑定事件都会触发此方法
process.nextTick(() => {
girl.emit(type)
})
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
// 逛街吃饭哭逛街吃饭哭逛街吃饭哭不哭
同步绑定
girl.on("newListener", function (type) {
//每次绑定事件都会触发此方法
console.log("start=>")
girl.emit(type)
console.log("end=>")
})
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("睡觉", function () {
console.log("不哭")
})
//start=>
//end=>
//start=>
//逛街
//end=>
//start=>
//逛街
//吃饭
//end=>
//start=>
//end=>
批处理
let set = new Set() // eventName
girl.on("newListener", (eventName) => {
// 每次绑定新事件 就会触发此方法
if (!set.has(eventName)) {
set.add(eventName)
process.nextTick(() => {
// 多次被合并成一次
set.delete(eventName)
girl.emit(eventName) // 主动触发的模式,我需要自己来触发对应的事件。 如果用户绑定了此事件就可以直接触发
})
}
})
// 失恋 [fn,fn,fn]
// 睡觉 [fn]
girl.on("失恋", function () {
console.log("逛街")
})
girl.on("失恋", function () {
console.log("吃饭")
})
girl.on("失恋", function () {
console.log("哭")
})
girl.on("失恋", function () {
console.log("哭")
})
发布订阅
function EventEmitter() {
this._events = {}
}
EventEmitter.prototype.on = function (eventName, fn) {
if (!this._events) this._events = {}
if (eventName !== "newListener") {
this.emit("newListener", eventName)
}
;(this._events[eventName] || (this._events[eventName] = [])).push(fn)
}
EventEmitter.prototype.emit = function (eventName, ...args) {
if (!this._events) this._events = {}
let eventLists = this._events[eventName]
if (eventLists) eventLists.forEach((fn) => fn(...args))
}
EventEmitter.prototype.off = function (eventName, fn) {
if (!this._events) this._events = {}
let eventLists = this._events[eventName]
if (eventLists) {
this._events[eventName] = eventLists.filter((item) => item != fn)
}
}
EventEmitter.prototype.once = function (eventName, fn) {
if (!this._events) this._events = {}
const once = (...args) => {
fn.call(this, ...args)
this.off(eventName, once) // 触发once函数后将once移除掉
}
once.l = fn
this.on(eventName, once)
}
8.fs模块
1).readFile、writeFile
const fs = require("fs")
const path = require("path")
// 读取⽂件要注意的是⽂件不存在会报错
fs.readFile(path.resolve(__dirname, "name.txt"), "utf8", function (err, data) {
// 写⼊操作默认会创建⽂件, 如果写⼊的⽂件有内容默认会清空在写⼊
if (err) return console.log(err)
fs.writeFile(path.resolve(__dirname, "copy.txt"), data, function (err) {
if (err) return console.log(err)
console.log(data)
})
})
// 问题:数据过⼤, 需要全部读取到内存中,会导致淹没可⽤内存。
2).⼿动读取
const buf = Buffer.alloc(3)
// flag 标识符:
// - 'r':以读取⽅式打开⽂件。如果⽂件不存在,报错
// - 'r+':以读写⽅式打开⽂件。如果⽂件不存在,报错
// - 'w':以写⼊⽅式打开⽂件。如果⽂件不存在,则创建该⽂件。如果⽂件存在,则覆盖。
// - 'w+':以读写⽅式打开⽂件。如果⽂件不存在,则创建该⽂件。如果⽂件存在,则将其覆盖。
// - 'a+':以读写⽅式打开⽂件。如果⽂件不存在,则创建该⽂件。如果⽂件存在,则可以读取⽂件,并在⽂件末尾追加数据。
// mode ⼆进制组合: 权限的组合,⽤户的执⾏权限,⽤户的写⼊权限,⽤户的读取权限 1直2写4读
// 0o666 的值代表了⽤户、组和其他⽤户都具有读取和写⼊权限。
fs.open(path.resolve(__dirname, "name.txt"), "r", function (err, fd) {
// fd file descriptor 数字
// 表示我要读取name.txt ,将内容写⼊到buf中, 表示从buffer的第0个位置写,写⼊3个, 读取⽂件的位置
fs.read(fd, buf, 0, 3, 0, function (err, bytesRead) {
// 真实读取到的个数
fs.open(path.resolve(__dirname, "copy.txt"), "w", function (err, wfd) {
// 我希望写⼊内容,那么需要读取buffer从第0个位置读取读到的个数,写⼊到⽂件的第0个位置
fs.write(wfd, buf, 0, bytesRead, 0, function (err, written) {
console.log(written)
})
})
})
})
3).递归拷⻉
function copy(source, target, cb) {
let readPosition = 0
let position = 0
function destroy(fd, wfd) {
let times = 0
function done() {
if (++times === 2) {
cb()
}
}
fs.close(fd, done)
fs.close(wfd, done)
}
fs.open(source, "r", function (err, fd) {
if (err) return cb(err)
fs.open(target, "w", function (err, wfd) {
if (err) return cb(err)
function next() {
fs.read(fd, buf, 0, 3, readPosition, function (err, bytesRead) {
if (err) return cb(err)
readPosition += bytesRead
fs.write(wfd, buf, 0, bytesRead, position, function (err, written) {
if (err) return cb(err)
position += written
if (bytesRead < 3) return destroy(fd, wfd) // 读取不到内容就关闭
next()
})
})
}
next() // 异步迭代可以通过递归函数来实现
})
})
}
4).⽂件流实现拷⻉
function copy(source, target, cb) {
let rs = fs.createReadStream(source, {
highWaterMark: 4,
})
let ws = fs.createWriteStream(target, {
highWaterMark: 1,
})
rs.on("data", function (chunk) {
let flag = ws.write(chunk)
if (!flag) {
rs.pause()
}
})
ws.on("drain", function () {
console.log("drain")
rs.resume()
})
}
copy(
path.resolve(__dirname, "name.txt"),
path.resolve(__dirname, "copy.txt"),
function (err) {
console.log("cp ok")
}
)
5).可读流
let rs = fs.createReadStream(path.resolve(__dirname, "name.txt"), {
flags: "r", // fs.open(path,flags)
highWaterMark: 3, // 每次读取的个数,如果不写默认是64k
start: 0, // start 和end 决定读取⼏个字节
end: 4,
autoClose: true, // 需要读取完毕后关闭
emitClose: true, // 底层会触发⼀个close事件,来通知我
mode: 0o666, // 我们的操作权限
})
rs.on("open", function (fd) {
console.log("open", fd)
})
let arr = []
rs.on("data", function (chunk) {
rs.pause() // 暂停后就不会再次触发data事件,可以消费读取到的内容,消费后再去读取
arr.push(chunk) // ⼀般情况下,客户端给我传递了⼀个图⽚,将图⽚拼接好写⼊到⽂件中
})
rs.on("end", function () {
console.log(Buffer.concat(arr))
})
rs.on("close", function () {
console.log("close")
})
rs.on("error", function (err) {
console.log(err)
})
setInterval(() => {
rs.resume() // 恢复流动模式
}, 1000)
实现原理
const EventEmitter = require("events")
const fs = require("fs")
class ReadStream extends EventEmitter {
constructor(path, options) {
super()
this.path = path
this.flags = options.flags || "r"
this.highWaterMark = options.highWaterMark || 64 * 1024
this.start = options.start || 0
this.end = options.end || undefined
this.autoClose = !!options.autoClose
this.emitClose = !!options.emitClose
this.flowing = false // 默认叫⾮流动模式
this.open() // 默认打开⽂件 //1s
this.on("newListener", (type) => {
if (type === "data") {
this.flowing = true
this.read()
}
})
this.offset = 0
}
destroy(err) {
if (this.fd) {
fs.close(this.fd, () => {
if (this.emitClose) {
this.emit("close")
}
})
}
if (err) {
this.emit("error", err)
}
}
pause() {
this.flowing = false
}
resume() {
// 这⾥可以恢复读取
if (!this.flowing) {
this.flowing = true
this.read()
}
}
read() {
if (typeof this.fd !== "number") {
return this.once("open", this.read)
}
const howMutchToRead = this.end
? Math.min(this.end - this.offset + 1, this.highWaterMark)
: this.highWaterMark
let buffer = Buffer.alloc(howMutchToRead)
fs.read(
this.fd,
buffer,
0,
howMutchToRead,
this.offset,
(err, bytesRead) => {
if (bytesRead) {
this.offset += bytesRead
this.emit("data", buffer.slice(0, bytesRead))
if (this.flowing) {
this.read()
}
} else {
this.emit("end")
this.destroy()
}
}
)
}
open() {
fs.open(this.path, this.flags, (err, fd) => {
if (err) {
return this.destroy(err)
}
this.fd = fd
this.emit("open", fd)
})
}
}
function createReadStream(path, options) {
return new ReadStream(path, options)
}
module.exports = createReadStream