1. HTTP 发展历程
⼀、 HTTP 发展历程
- 1991年
HTTP/0.9为了便于服务器和客户端处理,采⽤了纯⽂本格式,只运⾏使⽤ GET 请求。在响应请求之后会⽴即关闭连接。 - 1996 年 HTTP/1.0 增强了 0.9 版本,引⼊了 HTTP Header(头部)的概念,传输的数据不再仅限于⽂本,可以解析图⽚⾳乐等,增加了响应状态码和 POST,HEAD 等请求⽅法。 (内容协商)
- 1999 年⼴泛使⽤ HTTP/1.1,正式标准,允许持久连接,允许响应数据分块,增加了缓存管理和控制,增加了 PUT、DELETE 等新的⽅法。 (问题 多个请求并发 http`队头阻塞的问题)
- 2015 年 HTTP/2,使⽤ HPACK 算法压缩头部,减少数据传输量。允许服务器主动向客户端推送数据,⼆进制协议可发起多请求,使⽤时需要对请求加密通信。
- 2018 年 HTTP/3 基于 UDP 的 QUIC 协议
二、HTTP/0.9
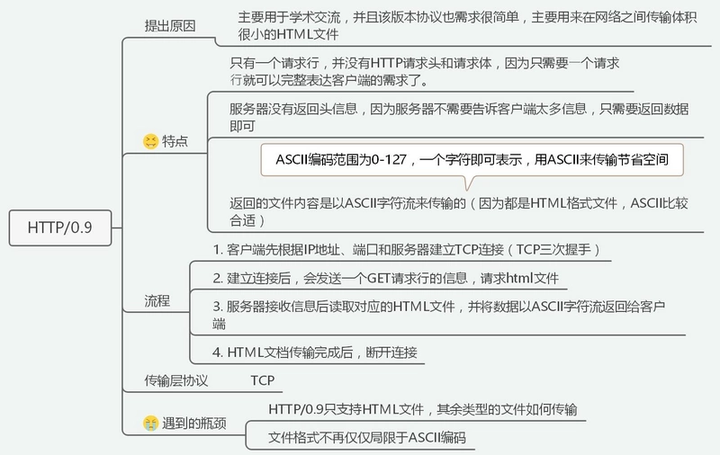
特点:
- 只有一个请求行;
- 服务器仅返回数据,没有响应头。
瓶颈:
- 仅支持 HTML,无法传输其他类型文件;
- 文件编码格式过少,仅局限于 ASCII。
- 如果请求的页面不存在,也不会返回任何错误码。
三、HTTP/1.0

特点:
- 引入请求头和响应头(数据类型、语言版本、编码类型、用户代理);
- 数据压缩;
- 引入状态码;
- 提供了 Cache缓存机制(head 里的缓存头:If-Modified-Since/Last-Modified 、Expires)。
瓶颈:
- 仅支持短连接,对于包含多个请求的文件,会大大增加开销;
- 串行文件传输,一个请求没有及时返回,会引起队头阻塞;
- 一个服务器仅支持一个域名;
- 因为在响应头中需要指定数据大小,因此无法接收动态生成的数据;
- 服务器只能传递完整的数据,而不能满足“只想要数据的一部分”这样的需求,会导致带宽浪费;
- 不支持断点续传。
- 每次数据传输,在 TCP 建立连接时,三次握手都会有1.5 个 RTT(round-trip time)的延迟。
四、HTTP/1.1
HTTP/1.1 是可靠传输协议,基于 TCP/IP 协议;
采⽤应答模式,客户端主动发起请求,服务器被动回复请求;
HTTP 是⽆状态的每个请求都是互相独⽴
HTTP 协议的请求报⽂和响应报⽂的结构基本相同,由三部分组成。
通过引入分块传输编码机制,支持动态内容;
HTTP/1.1中只优化了body(gzip压缩)
特点
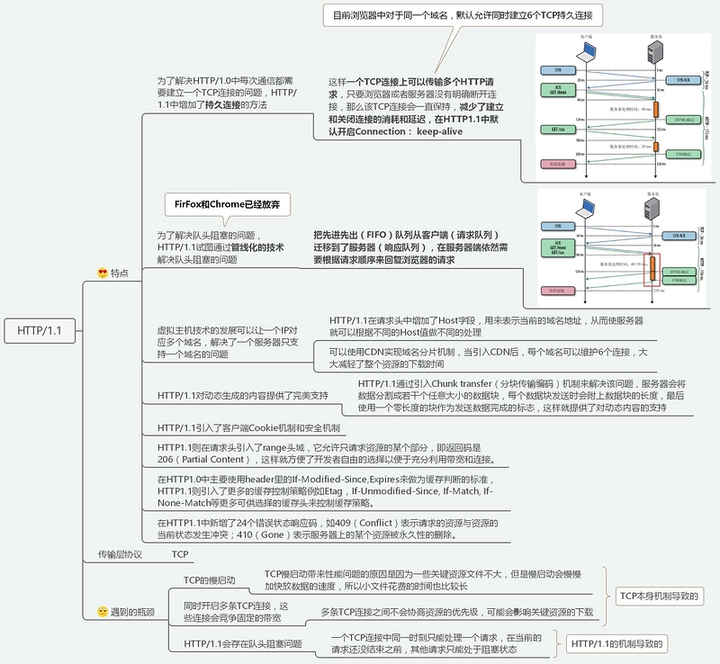
1. ⻓连接(持久连接)
TCP 的连接和关闭⾮常耗时间,所以我们可以复⽤TCP 创建的连接(最多 6 个)。HTTP/1.1 响应中默认会增加Connection:keep-alive
2. 管线化(已弃用)
如果值创建⼀条 TCP 连接来进⾏数据的收发,就会变成 "串⾏"模式,如果某个请求过慢就会发⽣阻塞问题。 Head-of-line blocking 管线化就是不⽤等待响应亦可直接发送下⼀个请求。
这样就能够做到同时并⾏发送多个请求
同⼀个域名有限制,那么我就多开⼏个域名 域名分⽚
3. host 字段
http1.1 中还新增了 host 字段,用来指定服务器的域名。
引入虚拟主机技术,让一个服务器可以支持多个域名;
4. 引入 range 头域(支持断点续传)
http1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,
http1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
5. 引入 Cookie与安全机制;
Set-Cookie/Cookie⽤户第⼀次访问服务器的时候,服务器会写⼊身份标识,下次再请求的时候会携带 cookie。通过 Cookie 可以实现有状态的会话
6. 优化缓存策略
强缓存 服务器会将数据和缓存规则⼀并返回,缓存规则信息包含在响应 header 中。 Cache-Control
协商缓存 if-Modified-Since/Last-modified (最后修改时间) if-None-Match/Etag(指纹)
7. 请求方法和状态码
http1.1 相对于 http1.0 还新增了很多请求方法,如 PUT、HEAD、OPTIONS 等。
http1.1 相对于 http1.0 还新增了 24状态码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
瓶颈:
- TCP 慢启动导致小文件建立连接过慢;
- 资源下载机制不完善,无法实现资源下载时的优先级调整;
- 一个 TCP 连接只能处理一个请求,请求头易阻塞。
HTTP/1.1中只优化了body(gzip压缩)并没有对头部进⾏处理- 当我们请求某个网址的时候,服务器能不能提前将页面需要的重要资源推送过来,而不是等待浏览器扫描 html 后再去加载?
- 既然多个 TCP 链接存在竞争关系,我们能不能让浏览器将针对同一个域名的所有 http 请求都基于同一个 tcp 链接呢?这样既减少了竞争,也减少了 tcp 链接的耗时操作。
五、SPDY:HTTP1.x 的优化
2012 年 google 如一声惊雷提出了 SPDY 的方案,优化了 HTTP1.X 的请求延迟,解决了 HTTP1.X 的安全性,具体如下:
- 降低延迟,针对 HTTP 高延迟的问题,SPDY 优雅的采取了多路复用(multiplexing)。多路复用通过多个请求 stream 共享一个 tcp 连接的方式,解决了 HOL blocking 的问题,降低了延迟同时提高了带宽的利用率。
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY 允许给每个 request 设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的 html 内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- header 压缩。前面提到 HTTP1.x 的 header 很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于 HTTPS 的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了 SPDY 的网页,例如我的网页有一个 sytle.css 的请求,在客户端收到 sytle.css 数据的同时,服务端会将 sytle.js 的文件推送给客户端,当客户端再次尝试获取 sytle.js 时就可以直接从缓存中获取到,不用再发请求了。SPDY 构成图:
SPDY 位于 HTTP 之下,TCP 和 SSL 之上,这样可以轻松兼容老版本的 HTTP 协议(将 HTTP1.x 的内容封装成一种新的 frame 格式),同时可以使用已有的 SSL 功能。
六、HTTP/2.0
特点
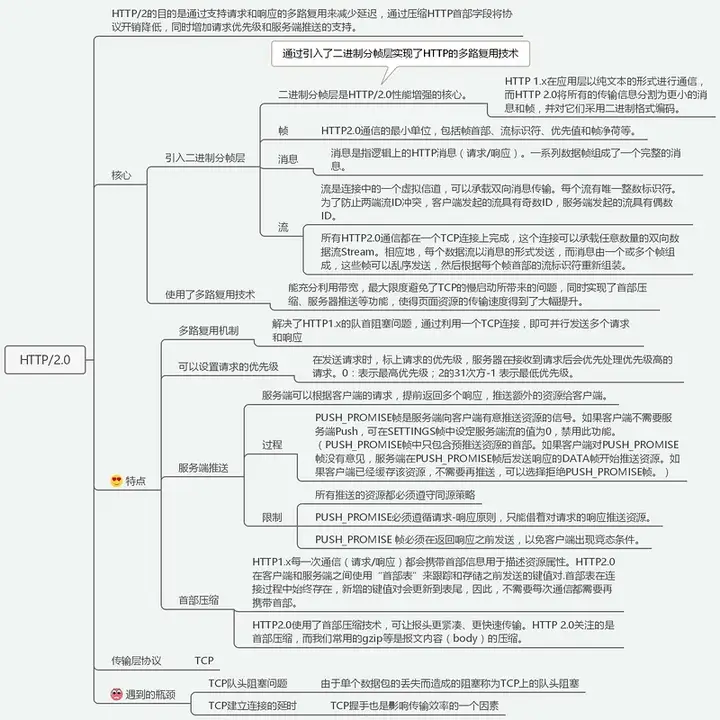
1. 多路复⽤
在⼀条 TCP 链接上可以乱序收发请求和响应,多个请求和响应之间不再有顺序关系
同域下采⽤⼀个 TCP 链接传输数据
引入二进制分帧层
HTTP/1.1 采⽤的是纯⽂本需要处理空⾏、⼤⼩写等。⽂本的表现形式有多样性,⼆进制则只有 0 和 1 的组合不在有歧义⽽且体积更⼩。把原来的 Header+body 的⽅式转换为⼆进制帧
HTTP/2虚拟了流的概念(有序的帧),给每帧分配⼀个唯⼀的流 ID,这样数据可以通过 ID 按照顺序组合起来
可以设置请求优先级;
2. 头部压缩
使⽤HPACK 算法压缩 HTTP 头
废除起始⾏,全部移⼊到 Header 中去,采⽤静态表的⽅式压缩字段
如果是⾃定义 Header,在发送的过程中会添加到静态表后,也就是所谓的动态表
对内容进⾏哈夫曼编码来减⼩体积
3.服务端推送
服务端可以提前将可能会⽤到的资源主动推送到客户端。
瓶颈:
- 单个数据包丢失会导致 TCP 上的队头阻塞;
- 握手产生的延时。
七、HTTP/3.0
HTTP/3 的来源
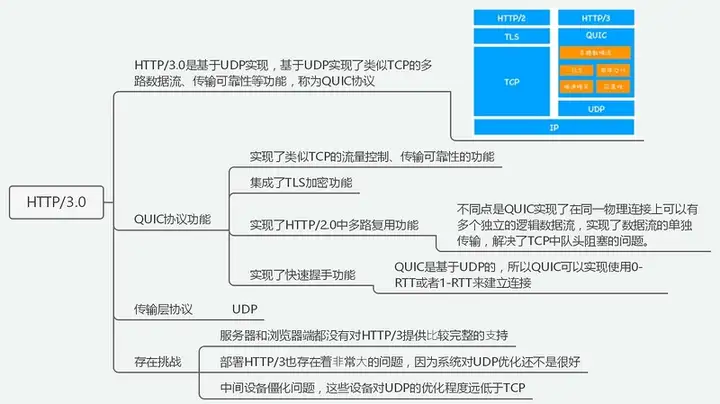
由于 TCP 和 UDP 两者在运输层存在一定差异,TCP 的传递效率与 UDP 相比有天然劣势,于是 Google 基于 UDP 开发出了新的协议 QUIC(Quick UDP Internet Connections),希望取代 TCP提高传输效率,后经过协商将 QUIC 协议更名为 HTTP/3。
QUIC 概述
TCP、UDP 是我们所熟悉的传输层协议,UDP 比 TCP 相比效率更高但并不具备传输可靠性。而 QUIC 便是看中 UDP 传输效率这一特性,并结合了 TCP、TLS、HTTP/2 的优势,加以优化。
于是在QUIC 上层的应用层所运行的 HTTP 协议也就被称为 HTTP/3。
HTTP over QUIC is HTTP/3
HTTP/3 新特性
特点:
1. 零 RTT 建立连接
如下图,传统 HTTP/2(所有 HTTP/2 的浏览器均基于 HTTPS)传输数据前需要三次 RTT,即使将第一次 TLS 握手的对称秘钥缓存也需要两次 RTT 才能传递数据。
对于 HTTP/3 而言,仅仅需要一次 RTT 即可传递数据,如果将其缓存,就可将 RTT 减少至零。
其核心就是 DH 秘钥交换算法。
- 客户端向服务端请求数据。
- 服务端生成 g、p、a 三个随机数,用三个随机数生成 A。将 a 保留后,将 g、p、A(Server Config)传递到客户端。
- 客户端生成随机数 b,将 b 保留后,用 g、p、b 三个随机数生成 B。
- 客户端再使用 A、b、p 生成秘钥 K,用 K加密 HTTP 数据并与 B 一同发送到服务端。
- 服务端再使用 B、a、p 得到相同秘钥 K,并解密 HTTP 数据。
至此即可完成一次 RTT 对连接的建立,当缓存 Server Config 后零 RTT 即可进行数据传递。
2. 连接迁移
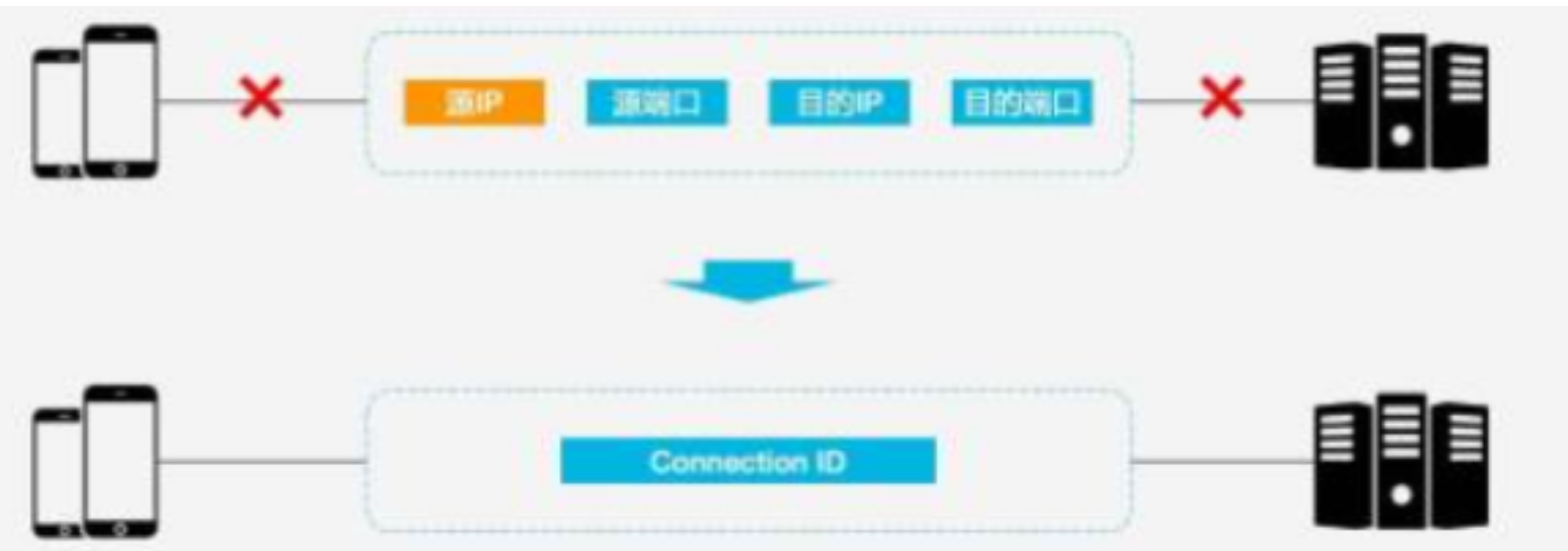
传统连接通过源 IP、源端口、目的 IP、目的端口进行连接,当网络发生更换后连接再次建立时延较长。
HTTP/3 使用Connection ID 对连接保持,只要 Connection ID 不改变,连接仍可维持。
至此即可完成一次 RTT 对连接的建立,当缓存 Server Config 后零 RTT 即可进行数据传递。
3. 队头阻塞/多路复用
TCP 作为面向连接的协议,对每次请求序等到 ACK 才可继续连接,一旦中间连接丢失将会产生队头阻塞。
HTTP/1.1 中提出 Pipelining 的方式,单个 TCP 连接可多次发送请求,但依旧会有中间请求丢失产生阻塞的问题。
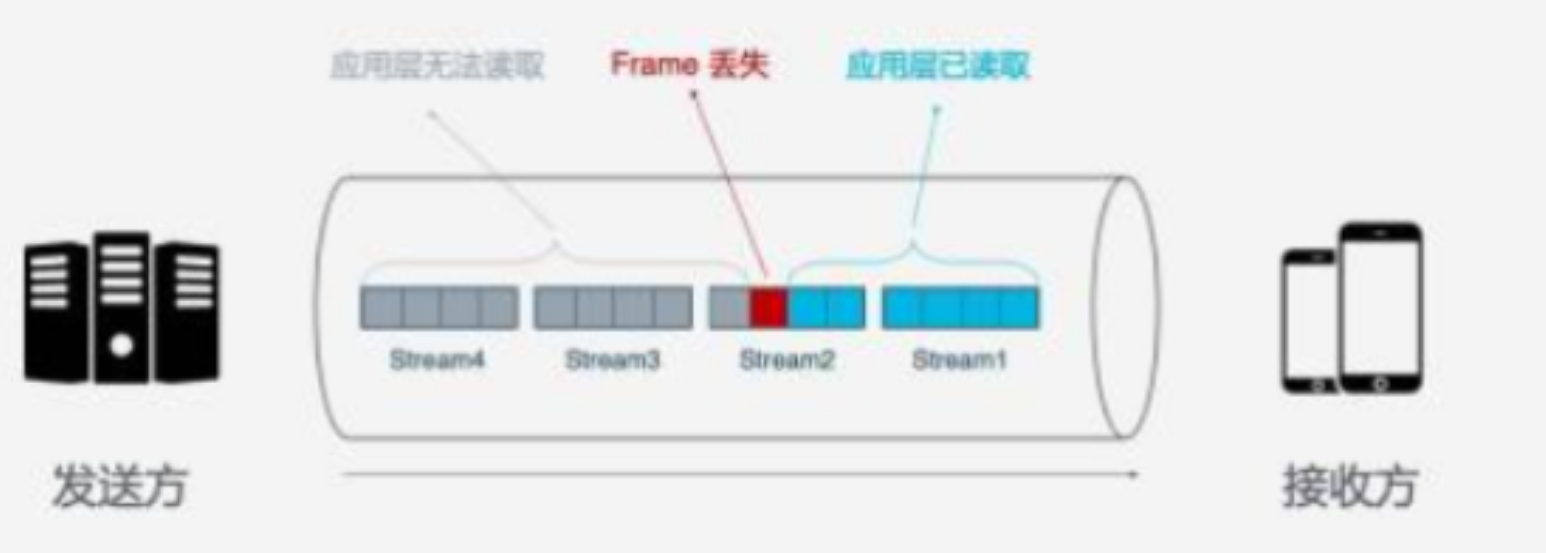
- HTTP/2 中将请求粒度减小,通过 Frame 的方式进行请求的发送。但在 TCP 层 Frame 组合得到 Stream 进行传输,一旦出现 Stream 中的 Frame 丢失,其后方的 Stream 都将会被阻塞。
- 对于 HTTP/2 而言,浏览器会默认采取 TLS 方式传输,TLS 基于 Record 组织数据,每个 Record 包含 16K,其中有 12 个 TCP 的包,一旦其中一个 TCP 包出现问题将会导致整个 Record 无法解密。这也是网络环境较差时 HTTP/2 的传输速度比 HTTP/1.1 更慢的原因。

- HTTP/3 基于 UDP 的传输,不保证连接可靠性,也就没有对头阻塞的后果。同样传输单元与加密单元为 Packet,在 TLS 下也可避免对头阻塞的问题。
4. 拥塞控制
- 热拔插:TCP 对于拥塞控制在于传输层,QUIC 可在应用层操作改变拥塞控制方法。
- 前向纠错(FEC):将数据切割成包后可对每个包进行异或运算,将运算结果随数据发送。一旦丢失数据可据此推算。(带宽换时间)
- 单调递增的 Packet Number:TCP 在超时重传后的两次 ACK 接受情况并不支持的很好。导致 RTT 和 RTO 的计算有所偏差。HTTP/3 对此进行改进,一旦重传后的 Packet N 会递增。
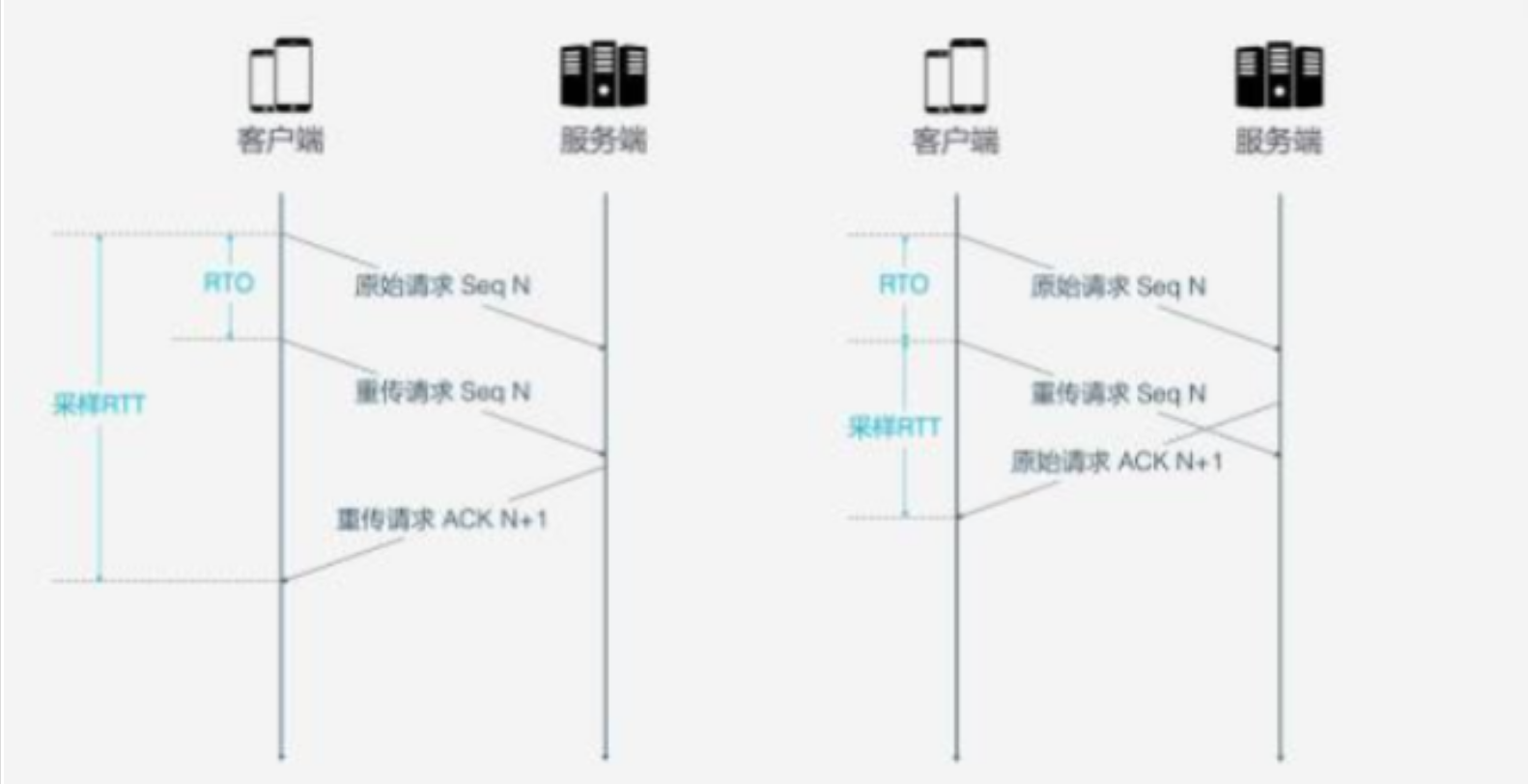
ACK Delay
HTTP/3 在计算 RTT 时健壮的考虑了服务端的 ACK 处理时延。
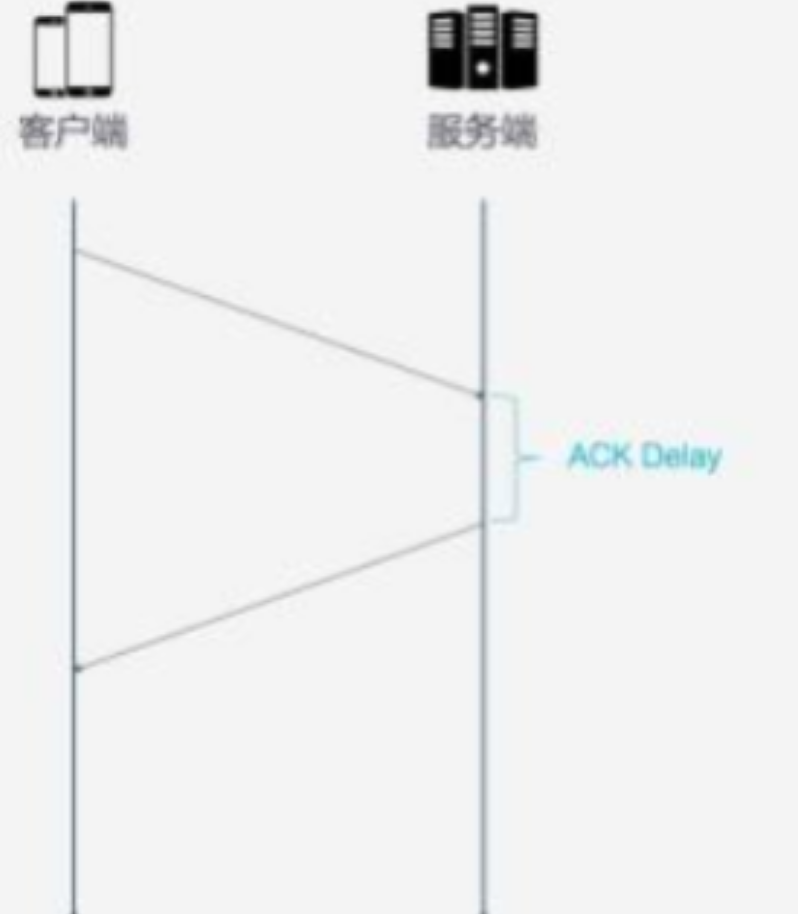
更多地 ACK 块
一般每次请求都会对应一个 ACK,但这样也会浪费(下载场景只需返回数据即可)。
于是可设计成每次返回 3 个 ACK block。在 HTTP/3 将其扩充成最多可携带 256 个 ACK block。
5. 流量控制
TCP 使用滑动窗口的方式对发送方的流量进行控制。而对接收方并无限制。在 QUIC 中便补齐了这一短板。
QUIC 中接收方从单挑 Stream 和整条连接两个角度动态调整接受的窗口大小。
瓶颈:
- 兼容性尚不完整;
- 优化程度不高。
HTTP 中的优化
- 减少⽹站中使⽤的域名域名越多,DNS 解析花费的时间越多。
- 减少⽹站中的重定向操作,重定向会增加请求数量。
- 选⽤⾼性能的 Web 服务器 Nginx 代理静态资源 。
- 资源⼤⼩优化:对资源进⾏压缩、合并(合并可以减少请求,也会产⽣⽂件缓存问题), 使⽤ gzip/br 压缩。
- 给资源添加强制缓存和协商缓存。
- 升级 HTTP/1.x 到 HTTP/2
- 付费、将静态资源迁移⾄ CDN